Exploring Eth2: Cost of Adding Validators
Adrian Sutton
Yesterday I spun up two new nodes on Prater, and sent deposits for 5000 validators to run on each. Due to the restrictions on how many new validators can activate per epoch (currently 4 for Prater), the number of active validators are currently gradually increasing giving a really nice insight into the cost of adding new validators.
This is most clearly seen by graphing the number of active validators and CPU usage on a single chart. Here the green is CPU usage and the yellow the number of active validators.
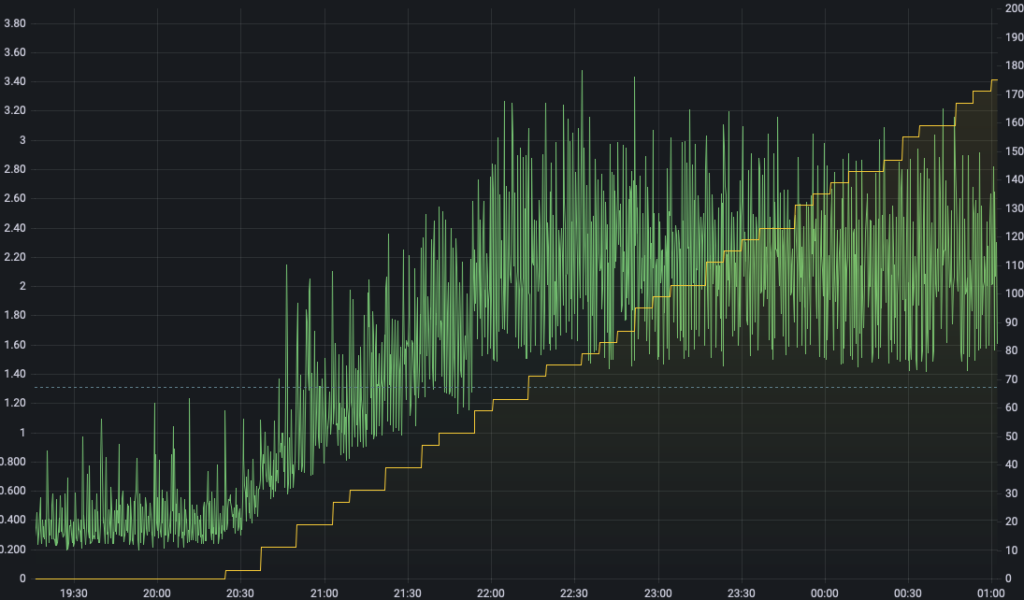
Once validators start activating we see CPU usage increase which is what we’d intuitively expect and for the first 60-70 validators there’s a clear correlation between adding validators and increasing CPU usage. However beyond about 70 validators the CPU usage flattens out even while the active validator count keeps increasing – why?
The answer lies in the way attestations are handled. To allow the beacon chain to scale to hundreds of thousands of validators, validators are assigned to separate committees. This sets not only which slot of the epoch they attest in (thus each slot only has 1/32 of the total validators attesting) but also which committee within that slot they are grouped into. There are a maximum of 64 committees per slot and each committee publishes their unaggregated attestations into a separate gossip topic. Then a subset of the validators in the committee are assigned to collect up those unaggregated attestations and publish an aggregated attestation which combines them.
Nodes with no active validators have no reason to subscribe to the gossip topics for unaggregated attestations so only process the aggregates. As validators activate though, each one is required to randomly select an attestation gossip topic to subscribe to long term and if they’re a validator need to subscribe to the topic they are aggregating for a period so they can collect and aggregate the individual attestations.
So for the first 64 validators the node winds up subscribing to an additional attestation gossip topic and processing 1/32 * total_validators individual attestations every slot. For prater that’s nearly 9,000 additional attestations per slot, for each active validator. No surprise then that CPU usage increases as we have to validate all of those attestations.
We see roughly the same correlation in the rate of gossip messages we receive. Here we’ve added gossip messages per second to the graph shown in blue.
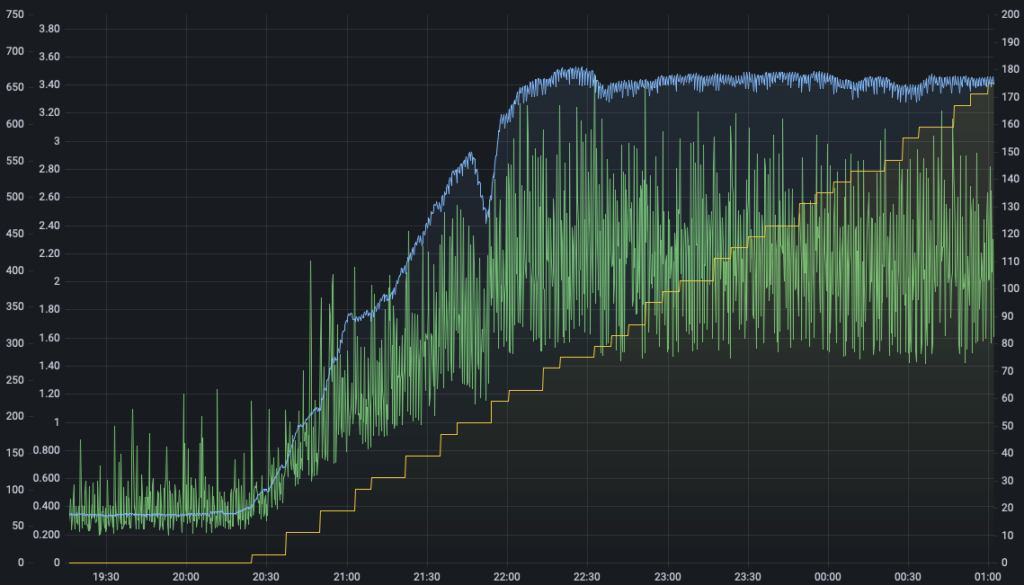
There’s a somewhat unexpected dip in gossip messages as the number of validators are ramping up – I think that’s actually a point where I restarted the node to apply some updates, somewhat ruining my pretty pictures…
Even so, we can see the very clear growth in gossip messages as the first validators activate, along with the increased CPU. Once we get to 64 validators activated both the CPU usage and gossip message rate levels off even as the validators continue to grow. At that point, we’re already subscribed to every gossip topic and processing every individual attestation. Adding more validators after that doesn’t take very much – they need to calculate their duties and produce one attestation per epoch, plus sometimes creating a block but that’s very cheap compared to validating all that attestation gossip.
So the first 64 validators you add to a node are quite expensive in terms of CPU usage and network traffic, but if you can run 64 validators well, then you can likely run thousands of validators well because you’re already processing the bulk of the attestations.
Of course, as the total number of validators continues to increase, nodes that are subscribed to all attestation gossip topics will have to process more and more attestations – they don’t get the benefit of the aggregation which is such a key part of the beacon chain scaling. For now it’s still quite manageable and there’s a fair bit of headroom left, but eventually large staking providers may need to start being smarter about how they manage attestation gossip requirements by spreading the duties across their fleet of nodes rather than having each node work independently. There’s a few ways that could work but that’s a story for another day…